C8.1 : L'encodage des caractères
Présentation
Encodage des caractères
Comme avec les nombres, lorsqu'on souhaite travailler avec des caractères, il est nécessaire d'attribuer un code binaire à chacun d'eux. Cela s'appelle l'encodage.
Les normes d'encodage ont évoluées, de 128 caractères dans les années 60 avec l'ASCII, on est passé à plus de 100 000 caractères avec les normes actuelles.
Utiliser un éditeur hexadécimal
Un éditeur hexadécimal est une interface (logiciel, application ou page web) qui permet de visualiser et éditer directement le code d'un fichier.
L'éditeur que nous utiliserons est une page web dont voici le lien : hexed.it.
L'ASCII
Présentation
L'ASCII (American Standard Code for Information Interchange) est la première norme d'encodage des caractères. Elle est apparu dans les années 60 et s'est progressivement généralisée.
Table des caractères de l'ASCII
Table des caractères de l'ASCII
L'ASCII permet le codage de 128 "caractères", chacun d'eux utilisant 7 bits.
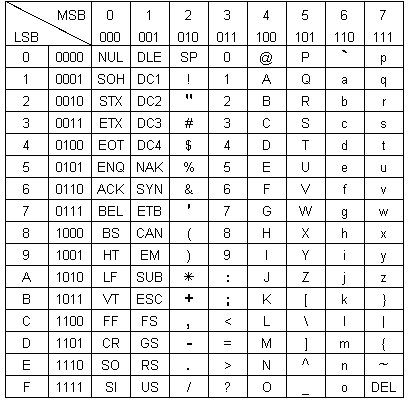
MSB : Most Significant bit ou byte (= bit/octet de poids fort)
LSB : Least Significant Bit ou Byte (= bit/octet de poids faible)
Lecture du tableau
Les bits de poids forts (MSB, Most Significant Bit) étant en tête de colonne, le tableau ci-dessus s'utilise en commençant par la colonne et en terminant par la ligne.
Exemple : le caractère Z sera codé 101 1010 en binaire soit 5A en hexadécimal.
Remarque : le tableau précédent existe également avec les lignes et les colonnes inversées.
Applications
1) Donner le code binaire et hexadécimal du caractère H.
2) Donner le caractère qui correspond au code 1010111.
L'encodage ISO-8859-1
Petit historique
L'ASCII ne permettant pas l'encodage des caractères accentués, en Europe occidentale, une autre norme a été proposée : l'ISO-8859-1 (parfois appelée Latin-1).
Cette norme intègre l'ASCI en lui ajoutant des caractères.
La table des caractères de l'ISO-8859-1

D'après la page de Wikipédia sur l'encode ISO-8859-1
Applications
Application 1 : Comprendre la lecture de la table
1) D'après la table ci-dessus, sur combien de bits chaque caractère est-il codé ?
2) La norme ISO-8859-1 est-elle compatible avec la norme ASCII.
Application 2 : Encoder un texte
On s'intéresse au texte "Hello !" représentée à l'aide de la norme ISO-8859-1.
1) Indiquer le nombre de bits nécessaires pour encoder ce texte.
2) Donner la représentation de ce texte en hexadécimal.
3) Donner la représentation de ce texte en binaire.
=> Vérifier votre réponse avec l'éditeur hexadécimal.
Application 3 : Décoder un code
On s'intéresse au texte encodé à l'aide de la norme ISO-8859-1 dont la représentation en binaire est la suivante :
0011 1010 0010 1101 0010 1001
1) Indiquer le nombre de caractères contenus dans ce texte.
2) Retrouver ce texte.
L'Unicode et ses encodages
Présentation
Avec l'augmentation de la puissance des machines et de la mémoire disponible, il devient possible d'envisager un encodage universel, c'est le but de la norme Unicode.
La norme Unicode
Principe général de la norme Unicode
Le standard Unicode (dans sa version 8.0) constitue un répertoire d'environ 120 000 caractères et symboles d'une centaine de langues.
A chaque caractère ou symbole est atrribué un nombre que l'on appelle point de code. Ces points de code sont notés U+xxxx (où x est un chiffre hexadécimal). La plage des points de code va de U+00000 à U+10FFFF.
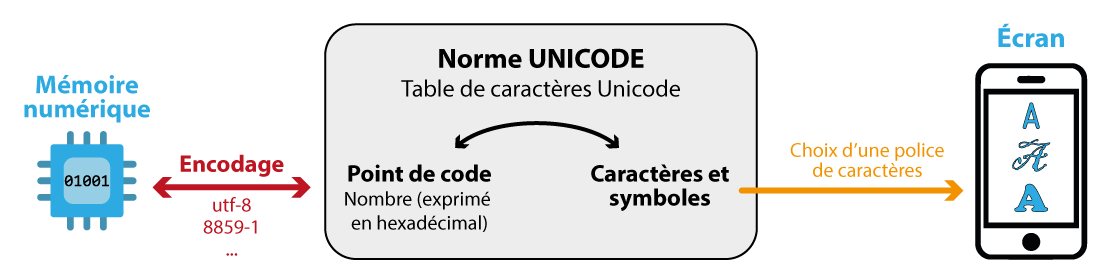
L'unicode ne définit pas la façon dont les points de code vont être représentés en mémoire par des 0 et des 1.
Les représentations des caractères à l'écran sont appelées des glyphes. Ces représentations dépend du choix de la police de caractère. Une police donnée ne dispose en général pas de glyphe pour tous les points de code !
Liste complète des points de code et des symboles associés de la norme unicode
Le lien suivant permet de visualiser la table Unicode complète.
Ex : Lettre majuscule latine A.
L'encodage des points de code
L'encodage ISO-8859-1 et la norme Unicode
Pour l'ISO-8859-1, les points de code des caractères sont identiques à leur représentation en mémoire.
L'encodage UTF-8
L'encodage UTF-8 utilise un nombre d'octets variable pour les différents caractères en fonction de l'importance de l'utilisation du caractère.
Voici le principe de l'encodage :
| Plage des points de code | Suite d'octets (en binaire) | bits codants | Remarques |
|---|---|---|---|
| U+0000 à U+007F | 0xxxxxxx | 7 bits | Codage sur 1 octet, compatible ASCII |
| U+0080 à U+07FF | 110xxxxx 10xxxxxx | 11 bits | Codage sur 2 octets |
| U+800 à U+FFFF | 1110xxxx 10xxxxxx 10xxxxxx | 16 bits | Codage sur 3 octets |
| U+10000 à U+10FFFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx | 21 bits | Codage sur 4 octets |
Remarque : le lien précédent (table Unicode complète) permet de visualiser différents encodages des points de code, dont l'UTF-8.
L'encodage UTF-32
L'encodage UTF-32 utilise 32 bits (soit 4 octets) pour coder tous les caractères de la norme Unicode
Application pour comprendre : l'UTF-8
1) A l'aide du lien précédent (table Unicode complète), rechercher le point de code ainsi que le codage UTF-8 en binaire du caractère é
2) Justifier, en décortiquant le rôle de chaque bit du code, la correspondance entre ces deux valeurs.
3) Quel est le code ISO-8859-1 du même caractère ?